TLDR: I tested several alternative coding models on the same Tetris clone task. Gemma4 failed immediately, DeepSeek V4 Flash produced a broken app, Kimi 2.6 made a working but slightly flawed game, and GLM 5.1 was the best overall. Sonnet with Opus as advisor was still strong and probably the safest option, but it used a lot of plan allowance and its final creative pass felt underwhelming.
The setup
Friday afternoon feels like a good time to share some testing I’ve been doing in my spare time with coding on alternative and smaller models.
This was prompted by the rising cost of frontier models. I wanted to see what other options were available, how capable they were in practice, and whether I could justify building a home LLM machine.
I used Opus 4.7 to generate a detailed step-by-step plan for building a Tetris clone. Then, using Claude Code as the harness, I gave that same task to several other models.
The idea was to test whether each model could follow a structured plan while still making sensible implementation choices along the way.
Note about costs: the coding harness was Claude Code, and all non-Anthropic models were run through Ollama Cloud on a plan. So the “reported costs” below are Claude Code multiplying token usage by some unknown cost. My guess is that this may reflect what the cost would have been if an Anthropic model had been used instead.
Here are the results.
Gemma-4-31b-it
This was the smallest model I tried, and the kind of thing you could potentially run at home on fairly modest hardware.
Result: total failure.
It could not get past step 1. It got stuck in a loop trying to decide whether to use file tools or bash to write files.
DeepSeek v4 Flash
- Token usage: around 60m total tokens
- Reported cost: around $300*
- Ollama Cloud usage: around 1% of weekly limit
This confidently delivered a result, but the game failed to load. All I got was a white screen.
So while it technically completed the task, the output was unusable.
It was also very inefficient compared with the other successful non-Anthropic models. GLM and Kimi both used far fewer tokens, with Kimi being slightly better on that front.
After those two failures, I stepped things up.
GLM 5.1
- Token usage: 28.1m input tokens, 54.7k output tokens
- Reported cost: $141.88*
- Ollama Cloud usage: around 2% of weekly limit
- Result: a functional game
It got a lot of the Tetris details right. There was at least one button that was not wired up properly, but overall it was very playable and genuinely fun.
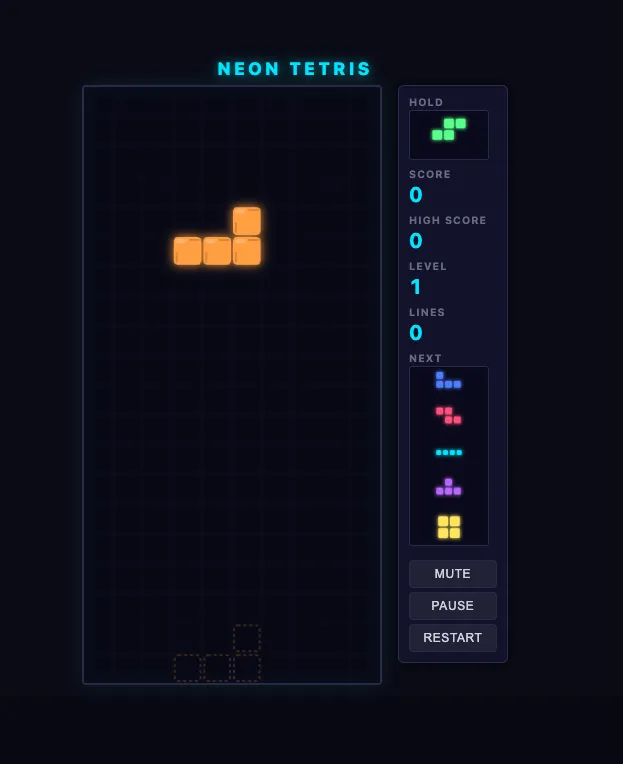
It was also much more token-efficient than DeepSeek.
Kimi 2.6
- Token usage: 19.2m input tokens, 67.6k output tokens
- Reported cost: $97.65*
- Ollama Cloud usage: around 2% of weekly limit
- Result: also a functional game
It was not quite at the same level as GLM, but it was a decent solution. The main issue was that there was no lock delay when pieces reached the bottom, so you could not shuffle a piece into its final position before it locked. That made it feel noticeably worse to play.
Kimi was the most token-efficient of the non-Anthropic models that produced a working result.
Sonnet 4.6 + Opus 4.7 Advisor
For reference, I also generated a Sonnet solution, using Opus as an advisor. As recommended in Claude Code. I did not use pure Opus because I did not want to remortgage the house.
- Token usage was reported differently when using Anthropic models:
- Haiku: 1.1k input, 37.5k output, 415k cached
- Sonnet: 2.7k input, 176.6k output, 1m cached
- Opus: 156.8k input, 23.7k output, 0 cached
- Cost: £13.85*
- On the Pro plan, this used 35% of my weekly allowance and around 2.5x my session allowance. It took three sessions to complete because of usage limits.
- Result: slightly ahead of GLM 5.1
It produced a good, playable, simple Tetris clone.
The Anthropic setup used the fewest tokens by quite a large margin, though Claude Code may be reporting token usage differently here. It is also possible that Claude Code is simply better optimised for Anthropic models, especially around tool use, caching, and session handling.
Creative round
After that, I gave the three successful models one more task: be creative and add finishing touches however they wanted.
Sonnet added combo tracking with single, double, and triple alerts. It also added particle effects, though they were not as strong as the others.
Kimi added combo and back-to-back tracking, particle effects, an updated HUD, screenshake, and richer sounds.
GLM added particle effects, slightly 3D-looking blocks, screenshake, a starfield background, score popups, combo text, a nicer ghost piece outline, border glows, and an improved game over screen.
My thoughts
GLM was the clear winner. It produced a strong playable result, used far fewer tokens than DeepSeek, and added the most interesting finishing touches when given room to be creative.
Kimi was also impressive. It was not quite as good as GLM in terms of the final game, but it was efficient and produced a working result.
Gemma4 was a useful reminder of the limits of smaller models, especially around tool use.
DeepSeek V4 Flash was the most frustrating result. It was confident, expensive in reported cost, and ultimately delivered something that did not work.
The surprising one was Sonnet. The core result was good, and the token usage looked much lower, though it may be reported differently. But the final creative pass felt quite lazy. It did the job, but it also felt like it did the bare minimum. That stood out, especially given that it was the most expensive option by quite some margin in terms of actual plan usage.
Conclusions
If you want the safest path to a working result, the Anthropic setup still looks good.
You get so much more for your money using Ollama Cloud and GLM/Kimi.